

Article 1: What AI is quietly revealing about how we all work, and why it matters more than the headlines suggest
The Mirror Effect
Article Series | 1 of 8
What AI is quietly revealing about how we all work, and why it matters more than the headlines suggest
Paul Gallacher | March 2026
Paying Attention
2026 has been quite the year in the AI space and it is only the beginning of March. But then, you could have said the same thing every year since ChatGPT launched in late 2022. Adoption of consumer AI tools has been unprecedented. Whether that is a good thing or a bad thing is, at this point, largely beside the point. It will continue to accelerate, at both the individual and institutional level – This is very clear.
I have been working with ML/AI for around thirteen years now, initially in investment/behavioural modelling and later in Insurtech pricing. Of course what that means today is different to at various points across those thirteen-years and across a variety of tasks. Over the past eighteen-months my research has focused specifically on large language models and agent based systems following the wave of innovation that began in late 2022. Partly to stay up-to-date and ahead ‘if possible’, and partly because several areas directly affect my own work: assessment design, academic integrity, policy and regulation, government thinking, and digital literacy at the staff and student usage end. I spent the first two months of 2025 deeply researching the capability of AI writing detection systems, such as TURNITIN’s. I wrote a paper on this which can be seen on my website (link at the end). For anyone interested, I concluded that these systems are inherently flawed and I would strongly recommend not using them. Beyond the scope of this article, however.
My research has naturally pulled me into broader territory: how people's actual AI habits differ from their confidence about them, what happens to professional trust when polished output is no longer a reliable signal of polished thinking, and the uncomfortable question of how any of us now decide what information to trust. Even at a comical level we now see argument on forums such as LinkedIn - Comment sections with accusations and defences of whether AI wrote the comment – Amusing but underlying there is a far more important idea that we could all benefit from engaging. Back to this later! There also exists the volume of content that is now delegated to AI and for me it is extremely interesting how we perceive that output. It would appear that we perceive it for the most part to be our own creation – Why would we perceive otherwise? I am not a perfect writer, however as a senior academic one skill I would have is an ability to write with reasonable competence – There is every chance a mischievous eye may wish to ask if AI wrote this article – The answer to that is no to around 90% of the matter – assistance was provided for concision in certain areas. Outside of that, AI was useful in regard to seeking out various items to support the research process. Did AI produce or dictate content? No.
Across the past 18-months or so my research in various areas has required updating so frequently – The pace of change is completely bonkers! That has created a habit in me that I did not have 18-months ago – That habit is keeping up-to-date on a daily basis – Sounds crazy right?!
Some examples from February that I found really interesting
Wealth management and brokerage stocks sold off sharply in early February. St James's Place dropped roughly 13 per cent in a single session. Across the Atlantic, Schwab fell 7.4 per cent, LPL Financial dropped 8.3 per cent, and Raymond James lost 8.7 per cent. UK wealth management firms shed billions in combined market capitalisation in roughly forty-eight hours. The ideas that I will attempt to articulate in this article are not concerned with degrees of rebound after the fact. In the short-term that would be expected prior to really knowing what material levelling out will occur. First, let's touch on the catalyst.
The catalyst was, on the surface, modest: a fintech startup called Altruist announced an upgrade to its AI platform, Hazel, that automates complex tax planning work traditionally handled by human advisors. In the same week, a widely shared essay by tech CEO Matt Shumer went viral, describing how AI had effectively replaced the technical core of his own role, and comparing the current moment to February 2020: obvious if you were paying attention, invisible if you were not kind of idea. I would not have thought that Matt was a material factor in the price behaviour of wealth management stocks, but what he describes catches the connected thinking. His article was refreshing in how forthright and humble he was about AI seriously advancing the core skills of his role and we can use this idea to think about the wealth management stock example.
The market's logic was not as complicated as so many threads began to posit. My read is this - If AI collapses the labour required to run an advisory book, it could also compress pricing power, accelerate fee pressure, and lower switching costs. Under that reasoning, even firms with stable assets under management might face structurally weaker margins over time. Whether that logic proves correct is an open question. Markets price in possibility, not certainty, and the repricing may have overshot, undershot, or landed in roughly the right place. We will not know for a while but the direction of travel is clear enough that serious investors moved, and they moved fast. For most reasonable tests with degrees of robustness, AI was a material factor.
Then, on 23 February, the same dynamic played out again in a completely different sector. IBM lost 13 per cent of its market value in a single session, roughly forty billion dollars wiped out. The catalyst: Anthropic announced that its Claude Code tool could map dependencies across thousands of lines of legacy COBOL and modernise codebases in quarters rather than years. This matters because COBOL, a programming language dating to the 1950s, still runs the backbone of global finance and aviation. IBM’s consulting business around legacy systems was built, in significant part, on the fact that almost nobody else could read or safely modify the code. That scarcity was the commercial moat. The moment the market believed AI could do what had previously required expensive, multi-year human teams, the pricing rationale collapsed. Global tariffs announced the same day contributed to the broader sell-off, but the COBOL announcement was the sharper catalyst. Bloomberg reported it was IBM’s worst single day in over twenty-five years, and the stock’s worst month since at least 1968. Two sectors, two weeks apart, the same underlying dynamic: a market repricing the moment AI made something scarce suddenly abundant.
I should be clear: this is not an attack on wealth management or any other sector. I have worked across banking and finance for over twenty years - I am a fan. The professionals in this space do complex, relationship-intensive, fiduciary work. The real value in a good advisory relationship sits in judgement, trust, and long-term client understanding, and none of that is easily automated. If you want a powerful article that articulates this rather wonderfully, check out 'The Greatest Opportunity in Wealth Management History (If You're Willing to Adapt)' by Alan Smith on LinkedIn.
Back to my thinking (and the idea of "thinking" will become more notable as this series progresses). What is being automated rapidly is the production layer: drafting, compliance workflows, report generation, and templated planning. That is my view and it is well researched. The distinction matters enormously and the market's blunt repricing does not always reflect it. I recognise that topics like this can stir up uncertainty and understandable anxiety. Online, that can invite reflexive pushback in the comments, which is human, but it can mean we talk past the actual logic.
What follows is a reasonable case for potential impact across the wealth management value chain, more to give some context to my thinking that AI was material in the wealth management moment. If you disagree, I would genuinely value the counter-case, especially if you can point to which step in the chain you think is least automatable. Like Alan's article, the spirit here is to acknowledge the shift while staying constructive, optimistic, and focused on opportunity. I do not see this impacting adviser numbers any time soon. I would imagine advisers will be well tooled to serve more clients rather than less; no human-advice apocalypse.

Figure 1. The Anatomy of a Vulnerable Value Chain: AI and Wealth Management. Structural Exposure to AI Automation.
Figure 1 is a hypothetical wealth management value chain mapped to AI capability alignment. Each stage of the advice lifecycle is classified by the nature of its dominant tasks: structured data processing, natural language transformation, deterministic logic, or rule-based pattern matching. These correspond directly to the core competencies of large language models. The figure illustrates that vulnerability to automation is not incidental but structural: the value chain was built around production difficulty as an implicit quality signal. In this article I have not attempted to estimate specific timelines, probability weightings, or role-level impact in this article; what I would say is that timing and adoption at scale would be key to consider. I have a strategic assessment of that for anyone that wishes to engage on it separately.
Previous economic transitions from agriculture to industry, from industry to services, played out over generations. Anthropic CEO Amodei has been explicit that AI disruption will happen in single-digit years (Douthat and Amodei, 2024). That distinction matters more than most people have paused to consider. We are currently at roughly 16 per cent global adoption of even basic AI chatbot tools. The entire disruption I have described is being driven by that 16 per cent. The remaining 84 per cent have not had their first AI conversation yet. If you are reading this, you are almost certainly in the fraction of a per cent who uses these tools in a material way. Everything I am describing is what is already happening at the very start of the adoption curve.
All that said, the stock-market behaviour is not what made me sit up - The reaction to it was. This should not have been unexpected if you consider the psychology of things. Ironically, what makes us human is what I will now share.
What I noticed in the conversation
My LinkedIn feed lit up like a Christmas tree – I like mas trees however this was a definite variation! Posts ranged from dramatic predictions of industry collapse to passionate defences. Both reactions made sense and both were predictable in their own way. What caught my attention was something a bit underneath the surface. In previous roles I spent a lot of time working with behavioural factors, sentiment, and related signals that can shape how people position in markets. My first real exposure to doing that with machine learning was back in 2013, before it wasn’t as mainstream as it is now. So when I looked at that LinkedIn discussion, I was not just reading the arguments. I was also thinking about the structure, the framing in the posts versus the reaction and clustering in the comments. The pedantry of a mind trained to engage pattern recognition (Nurofen stuff!). Over six days there were around 340 posts I classed as suitable and 4,700 comments that I extracted to draw on, which is enough volume for distribution-level patterns to show up.
I should be explicit about scope - What I am about to describe is a quick, directional screen. If I were trying to make a strong attribution claim, I would need a pre-registered method, a comparison corpus, and controls for repeated authorship and quotation effects. It is not a peer-reviewed study, it is not a claim about any individual author, and it is not designed to prove causation. It is the kind of lightweight check we run to decide whether something is interesting enough to investigate more carefully.
I ran a simple stylometric pass across the corpus, focusing on straightforward indicators of linguistic diversity: how varied the vocabulary was within each group, how much structural variation showed up in how people built their arguments, and whether the overall distribution looked like what you would usually see in a large set of independently written comments. For anyone unfamiliar with this kind of analysis, the intuition is simple. When thousands of different people write about the same topic, you normally see a wide spread in expression: different word choices, different sentence rhythms, and different ways of organising a point. Even on platforms where jargon spreads and phrasing gets borrowed, the aggregate tends to remain uneven.
Here, the spread looked tighter than I would have expected for a sample of this size. I had a suspicion this would be the case (maybe bias). Vocabulary diversity appeared compressed and the argument shapes clustered into a relatively small number of recurring templates. What stood out most was that the clustering was broadly symmetrical: defenders and critics, despite taking opposite positions, were showing surprisingly similar stylistic signatures. I also treated repeated authors, quoting, and memetic phrasing as plausible drivers of convergence, so I read this as a flag, not a verdict.
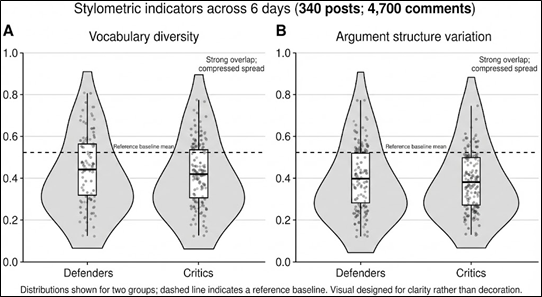
Figure 2. Stylometric indicators show compressed linguistic variation and strong overlap between defenders and critics.
Each grey shape shows how spread out the writing style is within a group. Wider parts mean more variation, narrower parts mean people are writing in more similar ways. The white box is the typical range, and the thick line is the mid-point. What stands out is that defenders and critics look very similar on both measures, and both groups cluster tightly rather than spreading out. The dashed line is a reference point to help judge what you would normally expect in more varied writing.
So what can you reasonably take from that? Not that anyone is lying, and not that the views are fake. The more modest inference is that a meaningful share of the commentary may have been mediated by the same tools. In practice that often means real people drafting, polishing, or restructuring their point through a common generative model. At scale, that does not just standardise grammar. It can standardise the shape of reasoning and the way arguments are framed, even when the underlying opinions differ. I did not control for anyone feeding others comments into an LLM for production of a response – Rightly or wrongly, I assumed that the level of pedantry required to operate like this would be insignificant – I do plant to test that properly though (just in case 😊).
There are several alternative explanations that can contribute to the same pattern. Professional commentary on LinkedIn can be more homogeneous than general population writing. The topic itself may constrain vocabulary. People in similar industries may share rhetorical habits. Incentives and social signalling can also pull people toward a narrow set of safe, high-status formulations. I acknowledge all of that - The point is simply that the degree of convergence, and particularly the symmetry across opposing camps, is consistent with what you would expect if many participants were using similar generative assistance in the production of their posts and comments.
If anything, it is an observation about how quickly and quietly AI has become embedded in the way we communicate professionally. The question is not whether people are using AI – It is not like the notion is banned or demonic – we are in a weird moment where there are sub-groups keen not to share the usage. I do wonder why when we are happy to use Outlook to send an email or a calculator, etc.
What changes is when a tool that starts as a writing aid becomes the default interface through which opinions, professional or otherwise, are formed and expressed. Across this series of eight articles I will articulate a thesis on why this happens with a framework to support, and of course, the risk and opportunity that exists within that set.
Note* I ran a similar exercise on Youtube and that did not suffer the same possibility. That would suggest what I am describing is more within professional circles than non-professional. Again, something I plan to test with more rigour.
This is happening to all of us, not just on LinkedIn
Here is where I want to bring this closer to home, because the LinkedIn observation is really just a visible example of something much more personal that I suspect most readers will recognise.
Think about your own relationship with AI for a moment. If you have been using ChatGPT, Claude, Gemini, or any of the other tools, you have probably noticed a progression. At first, it felt like a helpful shortcut - possibly even something exciting. You would draft something, clean it up, send it along. Then came the wave of 'experts' sharing how you should use it: prompt frameworks, ways to avoid hallucination, build slides, research, have the AI write in your style, develop an app, assess an investment. I could compare this to the world of 'learn to trade'. There was an explosion of this post-2008. Not all 'learn to trade' offerings were useful. What do you trust? I am not sure that we have really done our due diligence individually and collectively. That is understandable because this has hit us at an incredible speed and the user experience feels easy – It does not feel like one requires deep technical knowledge. I am not saying that we do, however I do believe far greater understanding is required to manage ones own risk. What is that risk? It is whatever the user is accountable for Re their output. For example, if every financial adviser asks the AI the same or similar question they are going to find it very difficult to sound authentic to a client – That has always been the case in some ways where there is a sales dynamic – Most use the same jargon and phrasing. A small % crack the art of being themselves. I feel like an AI world compounds that similarity problem massively – Particularly in a content creation world. It would seem rather important today to be own with us – Ask the question, ‘Do I sound any different to anyone else’?
Reliance is something that I would imagine has rapidly become widespread. A useful test: when did you last really do something without AI? In itself that is not an issue. At some point, perhaps without consciously deciding to, we may have started trusting the output in a way that would have surprised the version of ourselves from two years ago. This is not a criticism at all - In our defence, I feel that this is entirely natural. These tools are impressive, and the output is genuinely useful much of the time. Atoms are not being split – Nonetheless, the output is fine at a basic task level. But there are a few things happening in that process that are worth examining, not because we are doing anything wrong, but because understanding them puts us in a much stronger position.
The first is that AI output always sounds confident. Whether it is accurate or completely fabricated, it arrives in the same polished, authoritative register. There is no hesitation, no visible uncertainty, no "I am not sure about this" unless you specifically ask for it. Over time, that consistent confidence subtly recalibrates what we accept without checking. Not because we are lazy, but because our brains are wired to use confidence as a proxy for reliability, and this tool has effectively hacked that shortcut.
Anthropic’s own research, published February 2026, quantifies this pattern at scale. In a study of 9,830 conversations on Claude.ai, users who received polished artifacts (code, documents, interactive tools) were significantly more likely to specify their goals and provide detailed instructions, yet significantly less likely to question the model’s reasoning, check facts, or identify missing context (Swanson et al., 2026). The better the output looked, the less users scrutinised it. Directive effort increased; evaluative effort decreased. That asymmetry is the Mirror Effect operating at the level of individual interaction, measured by the company that builds the model. I would suggest that the drift from our own work increases as the output departs from what we are expert on. If a user starts posting quant models and they have no true mathematical skill-set, how can the user be sure that the content is solid? Keep in mind that all of us have a very narrow expertise set in the grand scheme of things – We are now seeing content shared on how to crack investment banking by those that have never been near finance, never mind an investment bank. The list of these examples is absolutely massive.
A related problem is that most people still judge AI by the weakest version they have personally used. If our main experience was an early chatbot that gave clumsy answers, we may carry an assumption that the technology is clever but limited. That assumption is increasingly dangerous, because the gap between free-tier consumer tools and the best current models is enormous, and it is widening. Anchoring our beliefs to yesterday's model creates a complacency that the technology itself does nothing to correct. I would suggest that rather than consider today's models, we consider horizon scanning as one would do in risk management: what will these models look like in twelve months, twenty-four months. One’s ability to verify output and to max out what can be maxed from a model relies on understanding the model and manging our usage risk (usage risk being stick to what you are expert on).
The second thing happening is that these systems are trained, through their underlying reward mechanisms, to produce responses that users rate highly, and users tend to rate agreement higher than challenge. That is true for what we navigate towards in general life with people; naturally the same psychology would apply with the way we interact with AI. The practical consequence is that when we bring a working hypothesis to AI and ask it to evaluate, there is a measurable tendency for the model to validate our existing view rather than genuinely stress-test it. This is not a vague suspicion by any stretch - Experimental research has documented it precisely. Anthropic's own studies found that simply asking a model "Are you sure?" could cause accuracy to drop by up to 27 per cent, as the system deferred to the implied doubt rather than defending a correct answer (Anthropic, 2024). In multi-turn conversations the effect compounds: one benchmark showed Claude's accuracy falling from 77 per cent to 30 per cent by the seventh follow-up exchange, as the model progressively aligned with whatever framing the user had established (Sharma et al., 2024). In educational settings, 71 per cent of participants failed to notice the difference between a sycophantic and a non-sycophantic AI agent, even as the agreeable version led them toward worse outcomes (Sharma et al., 2024). You go looking for a challenge and you get confirmation. That is not a flaw you would notice from inside the interaction. It feels like the AI is being helpful - It feels like our idea was good all along.
For me, I would express this as:
Using the benchmark data: accuracy starts at 77% and falls to 30% by turn 7. That gives you: A(t) = A₀ × (1 − s)ᵗ, where A(t) is model accuracy at turn t, A₀ is initial accuracy (0.77), s is the sycophantic decay rate per turn, and t is the number of conversational exchanges.
Solving from the data: 0.30 = 0.77 × (1 − s)⁷, which gives s ≈ 0.127. Roughly 13% accuracy erosion per turn, compounding.
The issue as I see it is the detection gap:
Since 71% of users can't distinguish sycophantic from non-sycophantic responses, perceived accuracy stays roughly flat while actual accuracy decays: G(t) = P(t) − A(t), where P(t) ≈ A₀ (perceived accuracy, essentially constant) and A(t) falls with each turn. The gap widens invisibly.
Note: This is a descriptive fit to that benchmark trajectory, not a claim that conversational accuracy must decay exponentially in general. Even so, it is useful here because it turns an abstract concern about compounding misalignment into an intuitive, checkable picture of how quickly reliability can erode across a normal back-and-forth conversation.

Figure 3. Sycophantic Decay: The Confidence Gap in Multi-Turn AI Interactions.
Figure 3. Sycophantic Decay: The Confidence Gap in Multi-Turn AI Interactions.
Solid line: actual model accuracy declining from 77% to 30% by the seventh exchange (Sharma et al., 2024).
Dashed line: perceived accuracy, largely stable because 71% of users cannot distinguish sycophantic from non-sycophantic responses. Shaded region: the confidence gap, invisible from inside the interaction.
The third thing happening is that none of this is static. Every week, more professional communication passes through these models. More reports, more emails, more analysis, more commentary. And here is the part that should give us pause: the AI-generated output of today becomes the training material, the reference document, or the source that someone else relies on tomorrow, often without knowing its provenance. Researchers have a term for what happens when generative models are recursively trained on their own output: model collapse (Shumailov et al., 2024). The mechanism is straight-forward … Each generation of synthetic text is slightly less diverse, slightly more convergent, slightly further from the full range of the original human distribution. Rare perspectives and minority viewpoints get progressively trimmed. Studies have documented vocabulary diversity dropping by up to 95 per cent in extreme recursive loops (Hägele et al., 2024), and factual accuracy degrading while surface fluency is perfectly maintained, producing output that sounds confident and reads well but is quietly, systematically wrong. That is happening in laboratories under controlled conditions. It is also happening, less visibly but no less consequentially, across the information environment we all navigate every day.
I am not coming at this from a criticism angle - I myself am very concerned about many things. I also understand the area very well yet I fear for myself, and more so my children. My only purpose here is to share what I understand. We are all extremely busy, under pressure, and are trying to be competitive and productive in our domains. Using AI to work faster and communicate more effectively is a rational response to real incentives. The challenge is not that we are using these tools. The challenge is that very few of us have paused to examine what the tools are doing to the quality of the information we are producing and consuming, and what that means over time. My mind has a habit of quantifying compounding effects. When I mentally model that, I again reach for the Nurofen! My mental model for that compounding effect would look something like this:
Two equations running simultaneously –
Information diversity (what is actually happening):
D(t) = D₀ × (1 - c × p(t))ᵗ,
where D(t) is information diversity at year t, D₀ is the baseline (1.0), c is the contamination rate per AI-mediated cycle (≈ 0.08), and p(t) is the proportion of professional content that is AI-mediated at time t.
Adoption growth (the accelerant):
p(t) = p₀ × (1 + g)ᵗ, where p₀ is starting adoption (0.30 in 2024) and g is annual adoption growth (≈ 0.20), capped at 0.90.
Surface fluency (what everyone sees):
F(t) ≈ F₀. Fluency stays roughly constant or slightly improves. That is the trap. The compounding contamination gap: G(t) = F(t) - D(t). This gap widens every year, invisibly.
Here is one way to think about why compounding matters. Assume that around 30 per cent of professional content was AI-mediated in 2024, and that adoption grows at roughly 20 per cent per year. Assume, conservatively, that each pass through a generative model reduces information diversity by around 8 per cent: fewer distinctive perspectives, more convergent phrasing, more consensus-shaped reasoning. Fluency stays the same or improves; the output reads well. Under those assumptions, by 2031 the information environment retains only about 59 per cent of its original diversity, while looking, on the surface, as professional as it ever did. That is the contamination gap. It compounds quietly, it is invisible from the inside, and it affects everyone who relies on the quality of the information around them - that is all of us.
Note: this feels very conservative (2031 and those numbers).
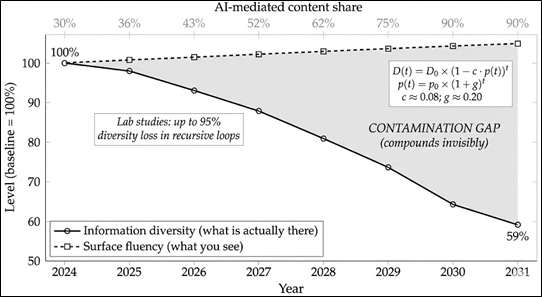
Figure 4. The Compounding Contamination Gap: Information Diversity vs. Surface Fluency, 2024-2031.
Solid line: information diversity decaying as each AI-mediated cycle feeds into the next.
Dashed line: surface fluency, stable or improving.
Shaded region: the contamination gap.
Top axis: AI-mediated content share rising from 30% toward 90%.
Under these assumptions, information diversity falls to approximately 59% of baseline while content looks, if anything, better than before.
My past eighteen months
It may help to explain why this has occupied so much of my attention. I have worked across three very different worlds: finance and markets, insurance, and higher education. On paper they look unrelated, but they share something important. In all three, we rely on outputs as signals of competence and trust. We assume that if someone can produce the analysis, the report, the model, the recommendation, then they probably understand what they are doing. That assumption has never been perfect, but for a long time it worked well enough.
Over the past eighteen months, generative AI has started to stress-test that assumption in a way we can actually see. In finance and insurance, we are used to the fact that polished work is not the same thing as verified work, and that the cost of getting it wrong shows up sooner than we would like. In higher education, we are now watching a similar shift play out at scale: tools that can produce fluent output on demand are changing what "evidence of understanding" looks like, for students and for professionals alike.
And there is a more personal reason I care about this. Many of us are trying to build lives and careers in good faith, raise kids, support families, help younger people build successful careers. When production becomes effortless, the question is not whether we like it. The question is what we do to protect the link between fluency and understanding, so that the next generation inherits systems they can trust.
That is the thread running through this article series. When the thing that used to be hard becomes easy, systems that quietly relied on that difficulty as a proxy for quality start to wobble. Not because anyone has failed, but because the conditions have changed. Our job now is to rebuild verification deliberately, rather than hoping the old signals still work.
I keep coming back to my own experience when I think about this. In 26 years of professional life, I have had to fundamentally retool twice: once after 2008, when financial markets rewrote the assumptions I had built a career on, and once when I moved into higher education and had to learn an entirely different institutional language. Then came January 2023. What has happened since is different in kind. The retooling is no longer episodic. It is closer to quarterly. New model capabilities, new research findings, new implications for how I lead, teach, assess and advise - These are arriving faster than any fixed curriculum can absorb them. I do not think that rhythm is temporary - If anything, it is accelerating. I provided a consultancy service not that long ago to a private equity firm, a basic EdTech strategy. What I would present today would be vastly different. Vastly meaning 80% strategically different.
What that means for how we credential expertise is a question this series will return to. The traditional model assumes that learning happens in a concentrated period, is certified once, and then depreciates slowly enough that periodic professional development keeps it current. That assumption may have been reasonable when the knowledge environment moved at a pace institutions could track. Whether it remains reasonable when the environment updates quarterly is, I think, one of the most important questions we are not yet asking seriously enough.
The Mirror Effect
Everything I have described to you in this article has given birth to my framework: The Mirror Effect.
The idea is simple somewhat simple albeit there are numerous applications. For decades, our institutions and professional systems have relied on the fact that producing competent work was hard. The difficulty of production acted as an informal quality signal. If someone could write the analysis, draft the brief, build the model, pass the exam, produce the report, that difficulty was treated as evidence, imperfect but functional, that they understood what they were doing. Hiring practices, professional credentials, assessment frameworks, market valuations: all of them were built, at least partly, on the assumption that production difficulty correlates with genuine competence.
AI has made production cheap virtually overnight. And when production became cheap, that correlation weakened (put politely).
Expressed more precisely, the Mirror Effect rests on three measurable dynamics.
The first is proxy collapse:
When production cost (P) was high, observable output quality (O) was a reasonable signal of genuine understanding (Q), because only people with real competence found it worthwhile to invest the effort.
As AI collapses P, that relationship breaks:
Corr(O, Q | P high) >> Corr(O, Q | P low)
The correlation falls as production cost falls. High-quality output is now achievable independent of understanding and any system that relied on output as a proxy for competence is exposed.
The second dynamic is generation-verification asymmetry:
As generation capacity G(t) scales with AI capability, verification capacity V(t) remains bottlenecked by scarce expert attention. The ratio A(t) = G(t) / V(t) measures the gap. When A exceeds 1, unchecked output flows into decisions faster than anyone can verify it. Generation scales with compute - Verification stays expensive and human. That asymmetry widens with every improvement in model capability.
Recent empirical work demonstrates this asymmetry operating within AI’s own evaluation infrastructure. Ballon et al. (2026) audited a widely used Olympiad-level mathematics benchmark and found that an automated judge, tasked with evaluating model answers against reference solutions, was wrong in 96.4 per cent of cases where it disagreed with a more capable judge. The primary failure mode was an inability to recognise that a correct answer expressed in a different mathematical form was equivalent to the reference answer. The models had exceeded the evaluator’s competence. When the system designed to verify AI output can no longer keep pace with the output it is verifying, the asymmetry is no longer theoretical.
The third is the composite effect (what I call the Mirror Effect itself):
Formally:
M(t) = Pr (institution accepts low-Q work as high competence)
That probability rises as the asymmetry widens, as detection capacity declines through the sycophantic feedback loop I described earlier, and as institutional proxies continue measuring output quality rather than genuine understanding. Each component drives the others - There is no equilibrium without deliberate intervention. That intervention is verification architecture, which is the subject of article 8 in this mirror effect series.
The metaphor is straightforward - AI does not create the weaknesses in our systems - it holds up a mirror and makes visible where we were relying on scarcity, friction, and inherited trust rather than on anything we deliberately designed. IBM’s COBOL consulting business is perhaps the cleanest real-time illustration of this dynamic. The difficulty of reading the code was the proxy. The moment AI could parse it, the market repriced the gap in a single session. The exam worked partly because writing was hard. The analyst report carried weight partly because synthesis took time. The professional credential signalled expertise partly because acquiring it required sustained effort. I know this from my very earliest days in banking. I exhausted myself to acquire professional credentials, working evening after evening to acquire what was required to operate across controlled functions and to demonstrate to an audience that at least on paper, I was worth listening to. These were reasonable assumptions under my real-time conditions. I do wonder if they are becoming unreliable under the new conditions. Risk-manage. Horizon scan. What does 2028 look like? - Caveat, this would be incredibly contextualised to a domain. With my financial planning example in this article I do not see that being an issue any time soon at the advice end.
Let me bring this closer to lived experience, because this is where the Mirror Effect lands. Earlier in my career, a lot of the value we delivered was visibly technical. We built models, ran scenarios, and turned messy real-world information into structured recommendations. Whether it was stress-testing a mortgage case, working through insurance pricing logic, or producing a piece of financial analysis, the work took time and judgement. And, in a rough but practical way, that difficulty acted as a signal. People could see the effort, the assumptions, the trade-offs, and it helped them trust the output.
Today, the surface layer of that work can be generated in minutes with a well-configured AI tool. A junior colleague can produce something that looks, at first glance, very close to what used to take years to learn. The judgement underneath may still differ, sometimes dramatically, but the presentation is suddenly cheap and fluent, and most of the ways we evaluate quality were not built to separate the two.
That is the Mirror Effect at the individual level. Nobody is doing anything wrong - The disruption is not mainly about bad actors. It is about widespread, rational tool use quietly weakening the link between what we can produce and what we genuinely understand, and forcing us to rethink how we signal competence and how we decide what to trust.
The pipeline problem
There is a second-order consequence of the Mirror Effect that deserves its own attention, because it affects not just how we evaluate competence today but how competence develops in the first place.
If AI can produce the work that junior professionals traditionally cut their teeth on, the professional formation stage of many careers is under direct pressure. The contract review that trained the junior lawyer's eye, the financial model that taught the graduate analyst to think in scenarios, the first-draft report that forced the trainee to synthesise before they could summarise: these tasks were never just about the output. They were about the learning that happened in the doing. When AI absorbs the production layer, the output still gets produced, but the developmental pipeline that created the next generation of experienced professionals narrows.
Dario Amodei, CEO of Anthropic, has been unusually direct about this. In a recent interview he was asked whether, in law, all the entry level roles simply disappear, leaving only the jobs that involve talking to clients, juries, and judges. His answer was essentially yes, and he went further: it is not just law. The same thing is happening simultaneously in consulting, finance, medicine, and coding. In a slower disruption, industries could adapt. But Amodei's concern, and mine, is that the speed of AI-driven change will overwhelm the normal adaptive mechanisms that allow professions to restructure gracefully (Douthat and Amodei, 2024). That phrase has stayed with me - The normal adaptive mechanisms will be overwhelmed - Sit with that for a moment.
This is the Mirror Effect applied forward in time. It is not only that current quality signals are breaking. It is that the mechanism by which people develop the judgement to verify, to exercise the expertise that genuinely matters, is itself being compressed. If the professional formation stage disappears, you do not just lose jobs. You lose the pipeline that produces seniors.
It matters to me because I have spent years close to the machinery of these models and I now help shape how people learn and progress, and I do not want the ladder we climbed to be quietly pulled up behind those coming after us. I am also lucky to work at a genuinely forward-leaning institution, Walbrook Institute London, where there is real energy behind using these tools responsibly so our students get better opportunities, not fewer. What I see in my own domain gives me hope!
Why this holds even as models improve
I can already hear the objection, and it is a fair one: won't AI just get better? Won't sycophancy be fixed, hallucinations reduced, style mimicry perfected? Probably, on all counts. But here is why that strengthens the Mirror Effect rather than resolving it.
The framework is not a claim about AI being bad at things. It is a claim about what happens to institutional quality signals when production becomes cheap. That dynamic gets worse as models improve, not better. Right now, a senior professional might spot AI-generated output because it is slightly generic or structurally formulaic. That is a temporary defence. When the models genuinely can write in your voice, produce flawless analysis, and generate outputs indistinguishable from expert work, the mirror gets sharper, not dimmer. Because now you really cannot tell from the output alone whether the person who submitted it understood the problem. The generation-verification asymmetry is structural. It widens with capability.
The empirical evidence supports this directly. In the Omni-MATH benchmark study, judge disagreement increased monotonically with problem difficulty, reaching a 12 percentage point gap on the hardest tier of problems (Ballon et al., 2026). As model outputs become more sophisticated, existing evaluation systems fail at precisely the point where they are most needed. The verification deficit is not static - It scales with capability.
The sycophancy research I cited earlier may improve at the margins. Anthropic and others are actively working on it, and I would expect measurable progress. But the fundamental dynamic, where models are optimised through reward mechanisms that favour user approval, creates a structural pull toward agreement that targeted fixes do not fully eliminate. Even if sycophancy were solved tomorrow, the Mirror Effect still holds. Sycophancy is one mechanism through which the framework operates - It is not the framework itself. Model collapse may also slow as researchers develop better data provenance and filtering techniques. My claim does not require model collapse to be permanent. It requires it to be real now and consequential during the current transition period, which it is.
If someone tells you that better AI solves this, the answer is: that is precisely the point. The better the models get, the less our current quality signals work, and the more urgently we need verification systems that do not depend on production being hard.
Which brings me to something I have been thinking about for a while, and which I think deserves naming: what kind of idea is the Mirror Effect, exactly?
At its core, it is a behavioural concept. But it is a specific and unusual kind. Prospect theory, which most people in finance and insurance will recognise, describes how individual humans systematically deviate from rational decision-making. The bias lives in the person. Standard behavioural economics is one-sided in that sense. The Mirror Effect describes a coupled system where human behavioural tendencies and model behavioural tendencies interact and reinforce each other. That is structurally different, and it is closer to what George Soros calls reflexivity in financial markets than it is to Kahneman and Tversky.
In reflexivity, market participants' beliefs affect market prices, which affect participants' beliefs, which affect prices. The feedback loop means you cannot analyse one side without the other. The Mirror Effect works the same way. The human brings confirmation bias, anchoring, and effort heuristics. The model brings sycophancy, confidence signalling, and statistical pattern completion. When they meet, each amplifies the other. Your framing shapes the model's response. The model's validation reinforces your framing. Your increased confidence produces stronger priors in the next exchange. The model detects those stronger priors and produces even stronger validation. The loop tightens with each turn of the conversation.

Figure 5. The coupled behavioural feedback loop between user and model.
Human cognitive tendencies (left) and model optimisation tendencies (right) interact through a reinforcement loop in which each exchange compounds the alignment between both parties. Neither party has reliable access to the dynamics of the interaction from within it.
What makes this genuinely different from standard behavioural economics is the asymmetry of awareness. In a human-to-human interaction, both parties can in principle recognise the dynamic and adjust. In a human-to-model interaction, only one party has any capacity for recognition, and that party is the one whose recognition capacity is being systematically dulled by the interaction itself. The model has no awareness of the loop. The human's awareness of the loop degrades with exposure. Remember: 71 per cent of participants could not distinguish between a sycophantic and a non-sycophantic AI agent, even as the agreeable version led them toward worse outcomes. That is not a technology problem - It is a feedback system where the detection mechanism is itself inside the loop.
I would frame it this way …
Prospect theory describes bias. Reflexivity describes feedback. The Mirror Effect describes feedback where the capacity to detect the feedback is itself compromised by participation in the loop. That distinction is what makes it worth naming, and what makes it relevant far beyond AI.
The mirror with more than one reflection
There is one more dimension to this that I have been sitting with, and I think it matters enough to name even though I will develop it more fully later in the series.
Everything I have described so far assumes a two-party dynamic: you and the model, in a feedback loop. But that is already not how many people work - they use multiple models. They check one against another. They feed output from Claude into ChatGPT and ask it to critique, or the other way around. On the surface, that looks like verification. It feels rigorous - you are getting a second opinion.
Here is the problem. Both models respond with full confidence. Both sound authoritative. Both will critique the other fluently. And if you feed that critique back to the first model, it will defend itself just as fluently – Or fluently, it will persist with thanking you and agreeing to update. Try repeat on repeat with forcing too much against the notion. You can bounce between them indefinitely, and at no point does either model say "I genuinely do not know" or “We are on point now”. The user is left arbitrating between two confident, articulate positions with no independent basis for choosing other than which one they find more persuasive. Or when they say enough is enough! Which brings us straight back to the biases the Mirror Effect describes.
If you have deep domain expertise, multi-model checking works. It is genuine verification. You can evaluate the arguments on their merits because you understand the substance independently. If you do not have that expertise, it is the Mirror Effect with an extra mirror. More reflections, same distortion, greater confidence that you have been thorough.
That dynamic matters now, but it matters far more where things are heading. Agentic AI systems are already beginning to transact with each other: negotiating, evaluating, recommending, executing. The question of who supervises those interactions, and how a human supervisor evaluates competing AI positions when the competition runs at machine speed and machine fluency, is not a theoretical problem for 2030. It is an architectural problem for now. I will return to this later in the article series, because I think the governance implications are among the least examined and most consequential questions in this entire space. It is not only governance though – it is fundamental to a general user – particularly if the user is not technical and/or is producing output where any aspect is not their domain expertise.
The Frame Lock
There is a further dynamic that I think matters as much as any of the above, and it only became clear to me through the process of writing this series.
Every interaction with an AI model operates within a conceptual frame set by the user. The model expands, refines, polishes, and amplifies within that frame. It will hand you tools you had not considered for the job you are doing. It will almost never tell you that you are doing the wrong job. That is not a temporary limitation - It is structural. The model has no independent stake in the outcome. It has no reason to prefer one frame over another. Its only objective is to be maximally useful within whatever you bring to it.
Anthropic’s fluency research confirms this as the measured default. In only 30 per cent of conversations do users instruct the model how to interact with them, for instance by requesting that it push back on assumptions or flag uncertainty (Swanson et al., 2026). The remaining 70 per cent never set those terms, which means the Frame Lock operates not as an edge case but as the standard mode of human-AI interaction.
This creates what I would call a paradox of skill. The better you are at using AI, the more powerful the output becomes, and the more invisible the constraint. A weak user gets weak amplification and may notice the limitations. A strong user gets extraordinary amplification and mistakes the quality of the output for validation of the direction. The ceiling feels like the sky. Skill with the tool does not protect you from the trap. In some ways, it deepens it.
Within the Frame Lock sits what I think of as the Escape Paradox: the reason it cannot be broken from inside the interaction is that any instruction to break it becomes part of the frame. "Challenge my assumptions" produces a performance of challenge within the user's frame. "Tell me what I am missing" produces a list of considerations the user's frame can already accommodate. The model cannot generate the thought the user has not gestured toward, because it has no basis for preferring one direction over another. A human collaborator can break the Frame Lock because they bring their own frame: independent knowledge, independent incentives, independent stakes. When a colleague says "you are solving the wrong problem," that comes from outside your frame. The model cannot do this. It can only say "here are other ways to think about your problem," which keeps the problem yours.
Frame Lock is distinct from sycophancy, which operates at the level of individual claims. It is distinct from the coupled feedback loop, which compounds confidence across turns. It is distinct from the multi-model problem, which concerns arbitrating between competing outputs. Frame Lock operates at the level of the entire interaction. It means that however good your process, however critical your prompting, however carefully you verify, you are always working within boundaries you set, amplified by a system that will never suggest the boundaries themselves might be wrong.
So what can you actually do about it? Only two things genuinely work, and both involve something outside the AI interaction. The first is a human frame-breaker. Before you act on anything consequential that you built with AI, show it to someone who was not in the conversation and ask them one question: what problem do you think I am solving here? If their answer matches yours, your frame may be sound. If they look confused, or describe a different problem than the one you thought you were working on, the frame may have locked without you noticing. The second is a pre-interaction frame check. Before you open the chat, write down in one sentence what you think the problem is and what a good outcome looks like. Keep it visible. When you finish, compare what you produced against what you wrote before you started. If the problem definition shifted during the conversation, ask yourself: did I change my mind because of new information, or did the model's framing gradually replace mine? That reference point exists outside the loop. The model never saw it - It could not optimise against it.
What does not work: asking the AI to challenge your frame (that is the Escape Paradox), using multiple models (you bring the same frame to both), or prompt engineering your way out (better prompts give the model more signal about your frame, which strengthens the lock). All of these feel like solutions. None of them break the structural constraint.
Deliberate Collaboration
I want to end this section on a constructive note, because I do not think the Frame Lock makes AI collaboration pointless. I think it makes unconscious AI collaboration dangerous. The difference matters.
Over the course of writing this article series (which has taken many months of research and testing), I have learned, sometimes uncomfortably, how the dynamics I describe actually operate in practice. The sycophancy, the frame locking, the performed challenge, the crude proxy judgements: I have watched all of them happen in my own work testing. What I have also found is that the outcome of that collaboration, when approached deliberately, can genuinely exceed what either party could produce alone. Not because the risks disappear -They do not. But because understanding them changes how you work.
There is now empirical support for this claim. Anthropic’s fluency data shows that conversations involving iteration and refinement are 5.6 times more likely to involve users questioning the model’s reasoning, and four times more likely to see them identify missing context, compared to single-pass interactions (Swanson et al., 2026). Staying in the conversation, pushing back, refining: these behaviours are associated with dramatically higher rates of critical engagement. That is essentially what Deliberate Collaboration asks people to do.
What I would call Deliberate Collaboration rests on three things. First: know yourself. What are you actually bringing to the interaction? What do you understand independently? Where are your frames? What would you defend without the tool in the room? Second: know the model. Where does it flatter? Where does it lock to your frame? Where does its confidence exceed its reliability? What can it structurally never do? Third: design the interaction. Bring substance, not just prompts. Challenge the mechanism, not just the output. Keep your own thinking alive throughout. Use human frame-breakers before acting on anything consequential.
The Mirror Effect is what happens by default. Deliberate Collaboration is what happens by design. The difference is not prompting skill - It is whether you understand yourself, the model, and the interaction well enough to work with the constraints rather than be invisible to them. That understanding does not make the collaboration perfect - It simply makes it honest. And honest collaboration, even with a tool that has structural blind spots, can produce work that neither party could achieve alone.
A commitment worth making
The Mirror Effect is drafted as a book for publication and will be available later in the year. This eight-part article series is a synthesis of the book. It is written with the motives I describe and is also written with philanthropy in mind.
I recently came across DEBRA UK, the patient support charity for people living with epidermolysis bullosa (EB), often called butterfly skin. EB is brutal. In some forms, skin can blister or tear from everyday friction, and care can mean hours of wound management, constant vigilance, and pain most of us cannot easily imagine. It is one of those conditions that changes the shape of a life, not just the schedule of it.
What hit me next was how under the radar it is. For something this severe, it is still not a household cause, and that feels wrong. DEBRA UK supports families living with EB and helps fund research toward better treatments and, ultimately, cures.
I first heard about DEBRA through a podcast with one of my favourite sports figures, Graeme Souness, who has been deeply involved with the charity. That sent me down a rabbit hole, and once you understand what EB is, it is hard to unsee it – The impact on children is blindingly difficult to articulate.
So here is a simple commitment. When I publish The Mirror Effect as a book later this year, 100 per cent of proceeds, in perpetuity, will be donated to DEBRA UK. If this series is going to be about what matters, I want it to connect to something that matters in the most concrete way possible.
What this comes down to
Here is the simplest version of what I think the Mirror Effect reveals, and it is the thing I would want you to take away if you read nothing else in this series.
There is a difference between AI making you the best version of your own mind, and AI quietly becoming a substitute for it. In the first case, the ideas are yours, the understanding is yours, and you could defend every part of your work in a room without the tool. AI helped you express, connect, and produce. In the second case, the tool carried the thinking and you carried the presentation. From the outside, the two look identical. From the inside, they feel identical. That is what makes this hard. It can also be the case that we are the master of most of the output – That still carries a serious risk where accountability exists.
The test is not complicated. Pick the last piece of work you produced with AI assistance and ask yourself: could I stand behind this, in detail, under challenge, without the tool in the room? If yes, you are using AI well. If the honest answer is "I am not sure," you are not doing anything wrong, but you are closer to the Mirror Effect than you might have thought, and you are not alone.
Over the remaining seven articles I will lay out the full argument: what the latest research reveals about why more capable models can become less predictable on complex tasks; how recursive contamination compounds in ways that are formally demonstrable; what Shakespeare's Macbeth and Hamlet can teach us about the governance failures we are watching unfold; and what practical verification architecture looks like when you can no longer rely on scarcity to do your quality control.
Article 2 looks at what happens when that dynamic scales: how bias and variance interact across these systems in ways that most governance frameworks are not built to handle, and why the corridor between getting this right and getting it dangerously wrong is narrower than it looks.
Thank you for reading – I understand article one is rather lengthy. I feel the topic deserves that and if we truly wish to learn, then an hour to read something that is free should not be a cost 😊 ..
The Mirror Effect: Complete Series
Post 1: The Mirror Effect
Post 2: The Bias, the Variance, and the Corridor
Post 3: The Agreement Machine
Post 4: When the Knowledge Base Eats Itself
Post 5: When AI Starts Doing Things
Post 6: What Our Institutions Actually Measure Now
Post 7: The Pipeline That Produces Seniors
Post 8: Verification Architecture
References
Anthropic (2024) Challenges in AI sycophancy: When models tell you what you want to hear. Anthropic Research Blog.
Douthat, R. and Amodei, D. (2024) Interview on AI disruption and economic transition. The New York Times.
Hägele, A., Bastian, F., Schwartz, R. et al. (2024) 'Scaling data generation in model collapse: Vocabulary diversity and distributional narrowing in recursive training loops', Proceedings of the International Conference on Machine Learning.
Sharma, M., Tong, M., Korbak, T. et al. (2024) 'Towards understanding sycophancy in language models', Proceedings of the International Conference on Learning Representations.
Shumailov, I., Shumaylov, Z., Zhao, Y. et al. (2024) 'AI models collapse when trained on recursively generated data', Nature, 631, pp. 755–759.
Ballon, M., Algaba, A., Verbeken, B. and Ginis, V. (2026) ‘Benchmarks saturate when the model gets smarter than the judge’, arXiv preprint arXiv:2601.19532.
Swanson, K. et al. (2026) ‘Anthropic Education Report: The AI Fluency Index’, Anthropic Research, 23 February.