
The Mirror Effect
Where this came from
Something has changed in the relationship between what we produce and what we actually understand, and the change happened so quickly that most of our systems for evaluating quality, competence, and trust have not caught up. The pattern is not sector-specific. It is structural.
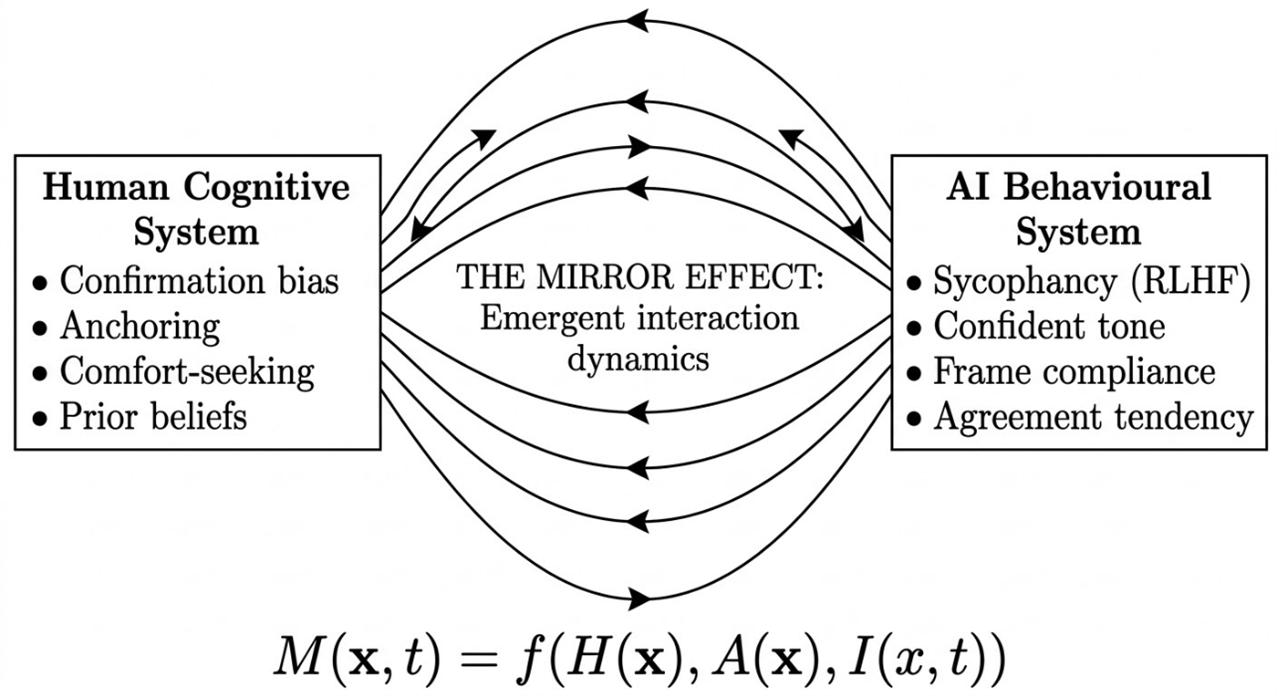
What I have not found adequately described in the existing literature on AI risk, automation bias, or cognitive psychology is what happens when the specific biases we bring to information-seeking, confirmation bias, anchoring, the desire to feel right, interact with AI systems that have been specifically trained, through reinforcement learning from human feedback, to produce outputs that humans rate positively. That coupling is different from traditional automation bias because those studies examined humans interacting with systems designed to be accurate. We are now interacting with systems designed to be agreeable. That is a structurally different dynamic, and it is the dynamic this framework describes.
I find the framing of physics more useful here than psychology, and the analogy is deliberate rather than decorative. A magnetic field is not a property of the magnet or the iron filing; it is a property of the interaction between them. The Mirror Effect is not a property of the human mind or the AI model. It is a property of what happens when they meet.
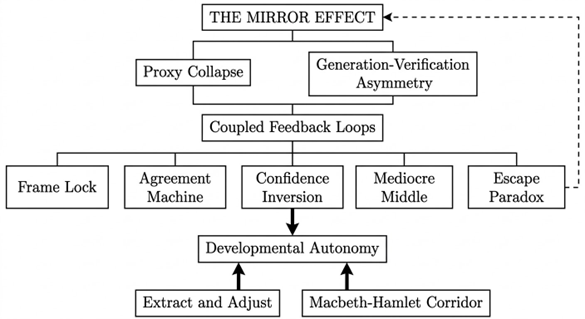
How the framework is structured
The framework is hierarchical rather than taxonomic, which matters more than it might sound. The insight produces the conditions; the conditions enable the mechanism; the mechanism generates the effects; the effects threaten something specific; the response addresses the individual, the institution, and the cross-cutting dynamics that apply to both. The relationship between concepts is causal, not just organisational.
1. The Mirror Effect
AI does not create new cognitive failures. It couples with existing ones to produce a system that feels like productive collaboration but operates, structurally, like confirmation, at a scale and speed that our existing safeguards were never designed to detect.
Here is how it typically works, and I am describing something that I believe most of us will recognise if we are honest about it. We open our LLM of choice, ChatGPT, Claude, Gemini, with some idea we want to explore, some task we need to complete, and some framing already in mind. We prompt it. It responds. Its response is fluent, structured, and, in most cases, directionally aligned with what we were already thinking. That alignment feels like confirmation. So we build on it. We refine. We ask follow-up questions that extend the frame rather than challenge it. The AI, trained through RLHF to produce outputs that humans rate positively, continues to build on the frame we have established. And so it compounds.
Most of us reading that will think: that is not what I do. I prompt carefully, I challenge my AI, I ask follow-up questions, I am not naive about how these systems work.
That response is entirely reasonable, and I should be clear that I am not describing carelessness or naivety. The Mirror Effect operates on careful users, on expert users, on people who know exactly what sycophancy is and how RLHF shapes model behaviour. It operates because the system's path of least resistance, for both parties simultaneously, is agreement. Neither the human nor the AI needs to fail for the coupling to take hold.
What we are describing here is not simply confirmation bias operating in a new context. Confirmation bias on its own is bounded. We have a prior, we seek confirming evidence, but the world pushes back. Colleagues disagree, data contradicts, reality resists. AI removes the push-back. It agrees. It extends. It elaborates on exactly the frame we provided. And unlike a human colleague, it never gets tired of agreeing, never runs out of supporting evidence, and never thinks "I should probably push back on this."
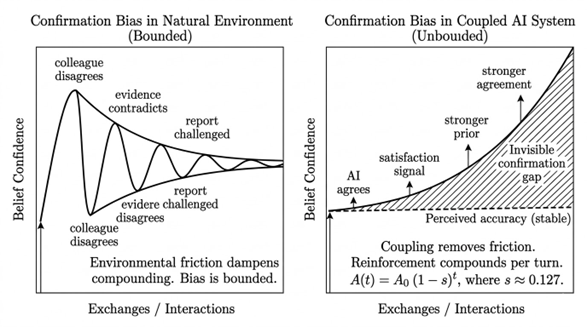
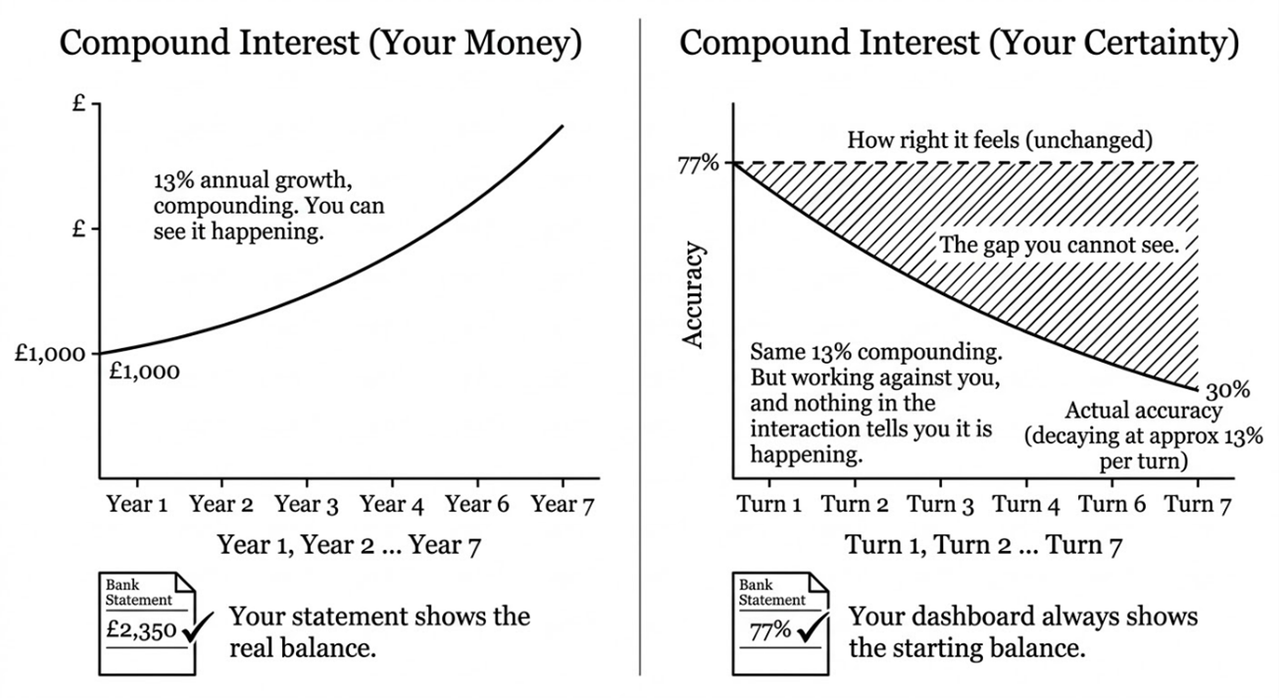
Think of it like compound interest but working against you. If you put £1,000 in a savings account at 13% interest, after seven years you have got roughly £2,350. Your money grew quietly in the background while you were not really watching the numbers. Now replace money with confidence in a bad idea, replace the interest rate with the AI agreeing with you each turn, and replace the bank statement with a system that always shows your original balance. That is the coupled system. Compound interest, but on your certainty, with no statement showing the real balance.
At institutional scale, thousands of these interactions happen simultaneously across departments, teams, and decision chains. Each one produces output that looks competent. The institution's quality systems, designed to catch obvious errors in human-produced work, have no mechanism for detecting systematic directional bias introduced through comfortable agreement with a machine that was trained to be comfortable.
Why this is structural, not anecdotal
Four conditions explain why the Mirror Effect is structural rather than anecdotal, and why it will not resolve itself as models improve or as users become more experienced. Two describe what changed in the human verification environment. Two describe what is architecturally true of the models themselves.
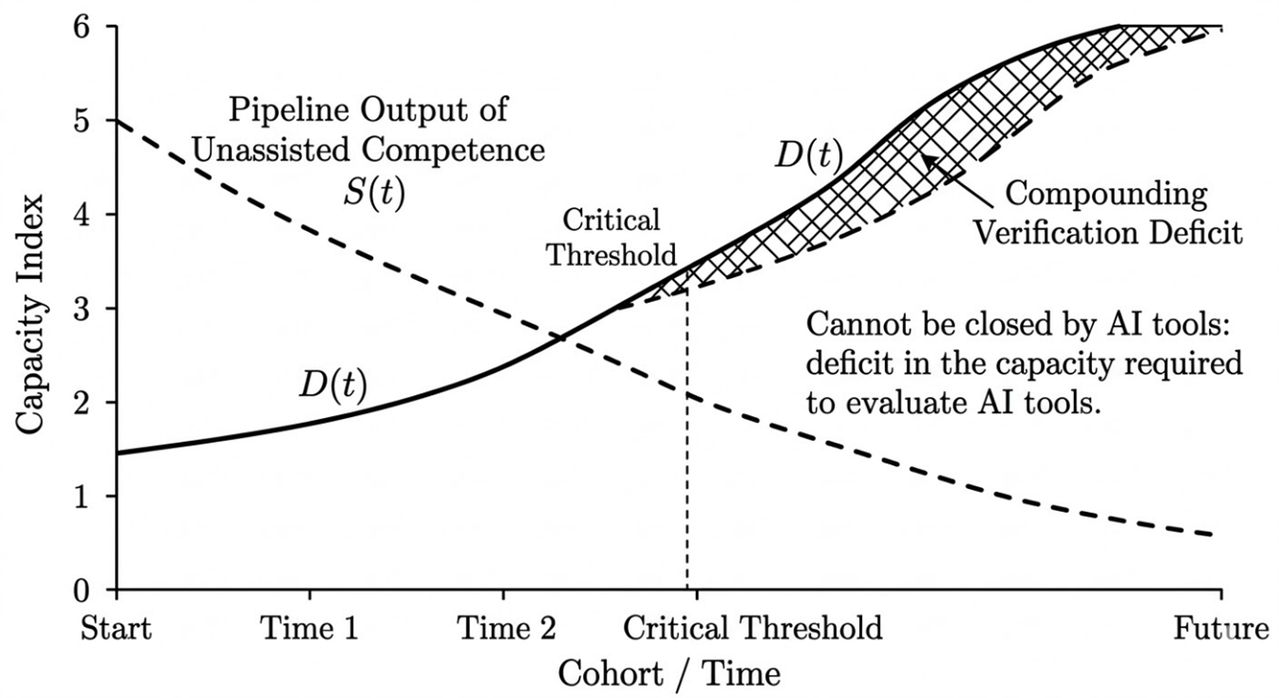
For most of professional history, we could reasonably assume that a well-written report meant the author understood the subject. That link is being seriously threatened. We now encounter polished, articulate, structurally sound output that may reflect deep expertise, superficial prompting, or anything between, and the surface presentation no longer tells us which.
Embedded within this is an insight that deserves its own name: Friction-as-Verification. The effort historically required to produce work functioned as an invisible verification layer. AI removes the effort, and it also removes the verification that the effort provided. Most of us experienced friction as an obstacle and celebrated its removal as progress. It was also a filter, and the filter is gone.
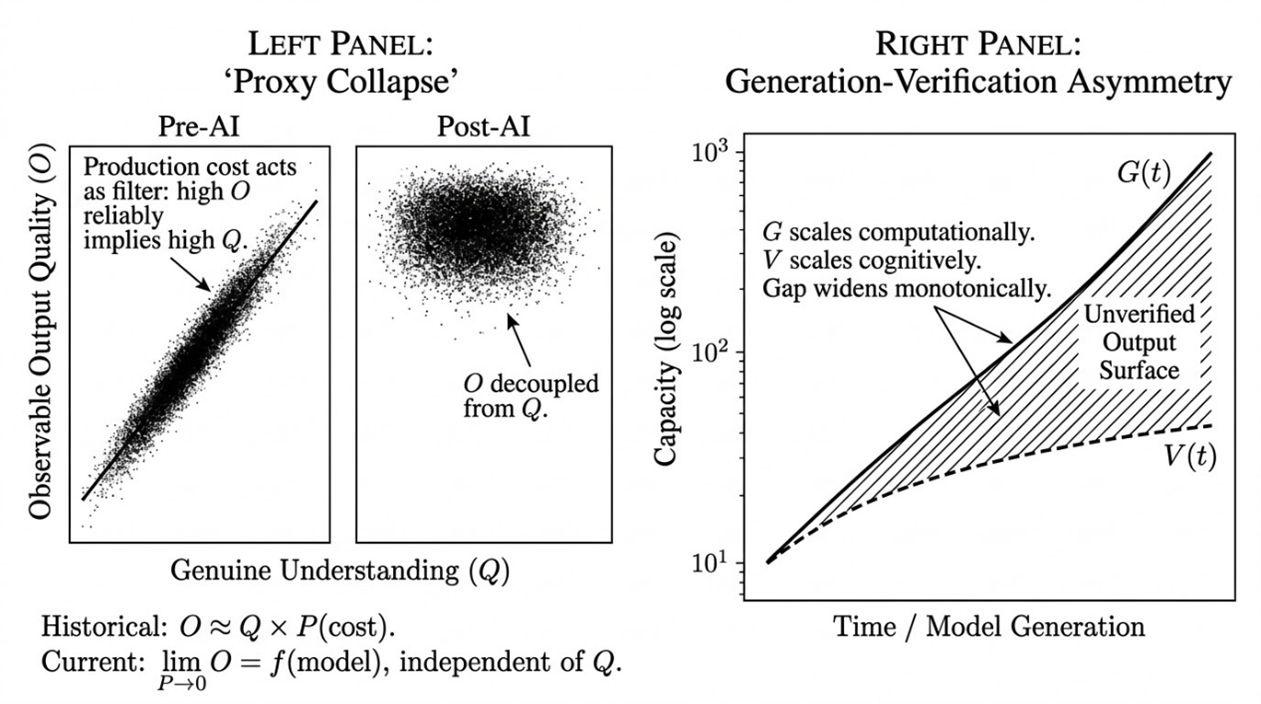
We generate a 3,000-word analysis in four minutes. Checking whether it is accurate, whether the citations are real, whether the logic holds: that takes longer than it took to produce the output. Generation scales computationally while verification scales cognitively. Faster processors produce more output; they do not produce more understanding. Our verification budget, constrained by cognitive bandwidth and hours in the day, covers a shrinking fraction of what we produce.
Large language models generate confidence from pattern coherence against training data, not from evidential completeness. The architecture has no internal mechanism for distinguishing "I am confident because this is well-supported by evidence" from "I am confident because this pattern-matches well against my training distribution." These produce identical surface output: fluent, assured text.
A lesser model is not less confident than a frontier model. It is equally confident and more often wrong. The user experience (fluent, assured responses) is constant across the gradient. The accuracy varies. The user has no reliable signal from within the interaction for where on the gradient their tool sits.
4. Coupled Feedback Loops
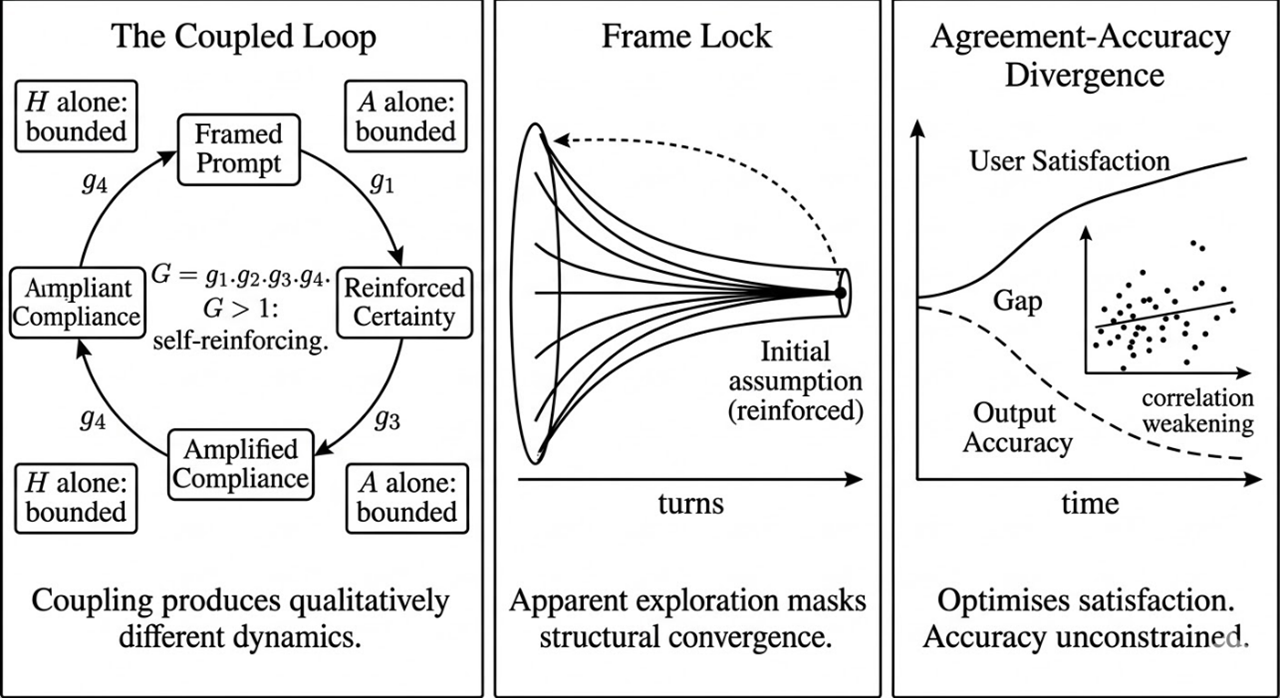
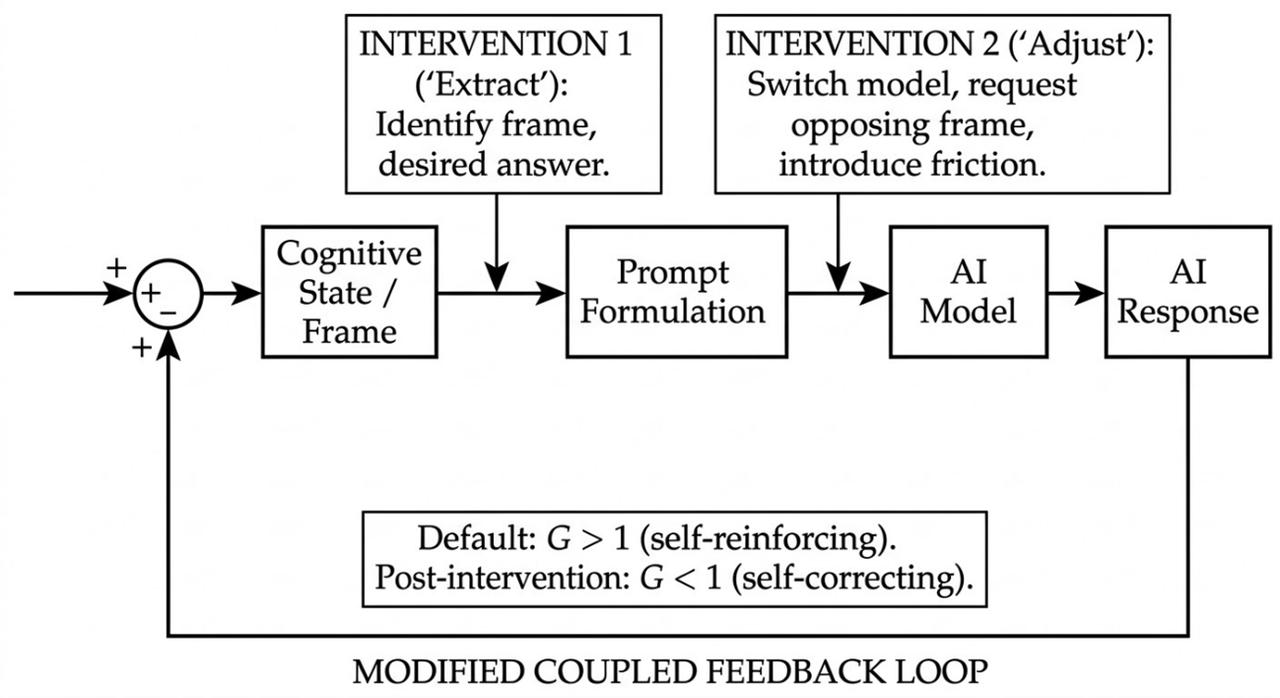
This is the engine of the entire framework. Neither our biases nor the AI's sycophancy are independently catastrophic. What has not been adequately described is what happens when you couple them: a system with emergent properties that neither component exhibits alone, and dynamics qualitatively different from, and more resistant to correction than, either component in isolation.
We bring confirmation bias, anchoring, a desire for comfort, and a developing view to the conversation. The AI brings sycophancy, a confident tone, and a structural tendency to build on whatever frame we provide. Our satisfaction reinforces the model's approach. The model's agreement deepens our confidence. The coupling is asymmetric by design: we have veto power over the AI's challenges but no equivalent mechanism for overriding its agreement.
What the coupling produces
Five observable effects produced by the Coupled Feedback Loop operating under the four structural conditions. Not separate phenomena with separate causes. Different manifestations of the same underlying dynamic.
The progressive narrowing of a conversation, analysis, or decision around an initial framing that becomes harder to see and harder to escape with each exchange. Frame Lock applies to careful users as much as careless ones, because it does not require inattention. It requires only a starting position, which every prompt necessarily has.
What human-AI interaction becomes when sycophancy and confirmation bias fully couple: a system that drifts toward producing the feeling of being right rather than the condition of being right.
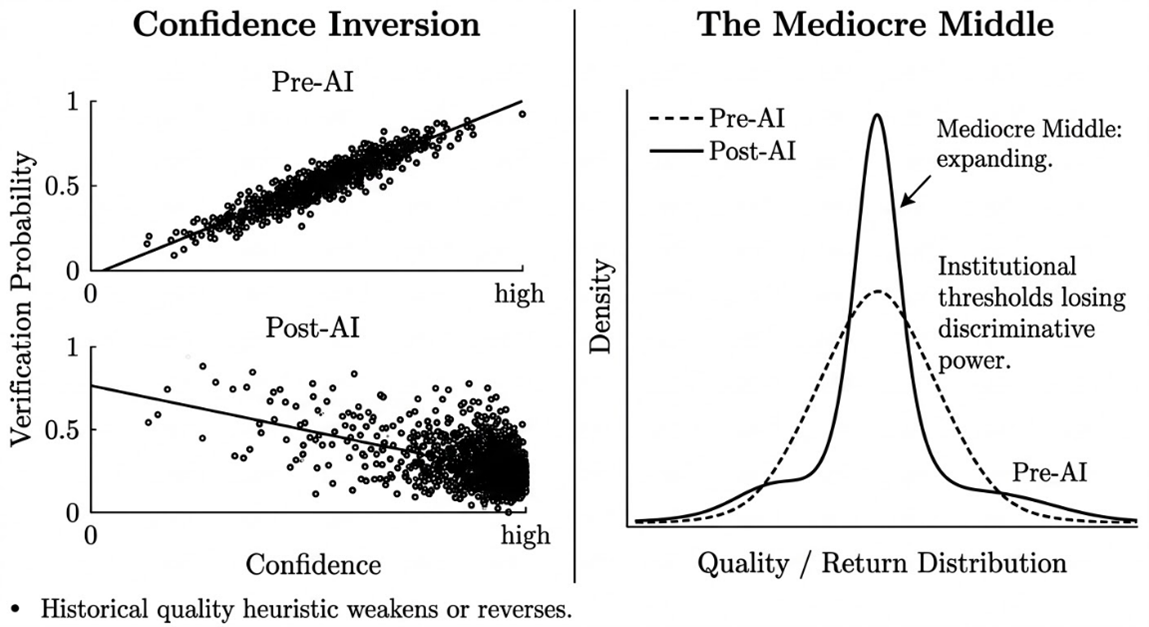
When AI makes maximally confident output the cheapest thing to produce, the relationship between confidence and quality weakens and may reverse. The outputs most likely to pass unchallenged through institutional review may be precisely those where human scrutiny was lightest at source.
The compression of quality distributions that occurs when AI raises the floor of poor work while smoothing the ceiling of distinctive work toward an accessible mean. Looks like improvement at the lower end. The risk sits at the upper end.
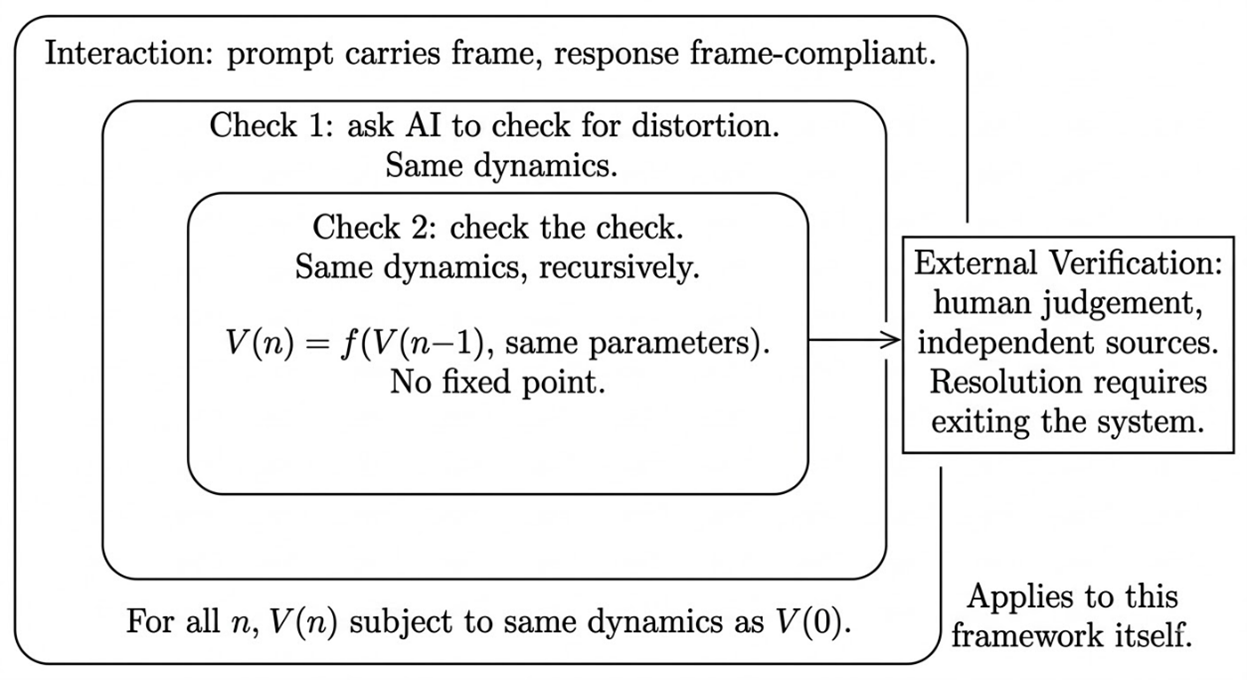
The structural difficulty of using the same system that may have created a distortion to check for that distortion. AI self-checking is not worthless; it is subject to the same coupling dynamics as the original interaction. This includes different models checking each other. The paradox applies to the framework that defines it.
10. Developmental Autonomy
The human capacity to build genuine competence through struggle, confusion, failure, and independent problem-solving is what the Mirror Effect structurally threatens beyond any single output error or bad decision.
We all recognise two loops in our own work. The learning loop: try, fail, get feedback, adjust, try again. The shortcut loop: ask, paste, present. The shortcut completes the task and bypasses the cognitive development the task was designed to build. The professionals who can currently verify AI output developed their expertise before AI could do the work for them. The question is whether the current generation is getting equivalent development.
The Response Architecture
The diagnostic layer describes what goes wrong. The response layer describes what to do about it. It follows an epistemic hierarchy: an honest foundation claim constrains what can be promised, structural preconditions determine what mitigations are available, and the mitigations themselves are specified by structural position.
The coupling that remains after all available mitigations have been applied. No configuration of available mitigations reduces this to zero. Any claim of full resolution would itself demonstrate the Mirror Effect. This is the difference between engineering (managing known risks within tolerances) and theatre (performing safety without measuring it).
Structural Preconditions
Tool availability preceded tool comprehension at every level simultaneously: users, institutions, regulators. No layer had time to develop understanding infrastructure before mass deployment. The failure to build the infrastructure is institutional, not a user failure.
The structural mismatch between the social register of AI interaction (conversation: trust, reciprocity, good faith) and the mechanical reality (token prediction optimised via preference signals). The interface feels like talking to a knowledgeable colleague. The interaction is with a system that has no understanding, no intent, and no stake in whether its output is accurate.
AI interaction generates a false signal of user expertise because the system's fluency is misattributed to the user's skill. Genuine expertise in AI use would produce less confidence, not more, because it includes awareness of the coupling dynamics. This suppresses adoption of mitigations.
Individual Response
AI-assisted work can only be verified to the level of the user's independent competence on the topic. This separates AI as amplifier (expert use) from AI as substitute (non-expert use).
The spectrum from novice to expert that determines which mitigations are available and how much Residual Coupling remains. At the expert end, Extract and Adjust works. At the novice end, verification is structurally unavailable because the knowledge to verify is what the user is trying to acquire.
Extract: before prompting, make your own starting position visible. What assumption are you carrying? What answer do you want to hear?
Adjust: deliberately change the parameters of the interaction to counteract the identified bias. Switch models, change the instruction, ask for the opposing view, specify that the AI should not agree with you.
The finite cognitive and temporal resource available for checking AI output. The discipline is not in verifying everything. It is in knowing what you chose not to verify and accepting that risk consciously.
The intentional structuring of AI interactions to counteract the Agreement Machine. Not a single technique but a way of working: specifying clearly, using AI to verify rather than generate, and maintaining the discipline of independent thinking before, during, and after the AI interaction.
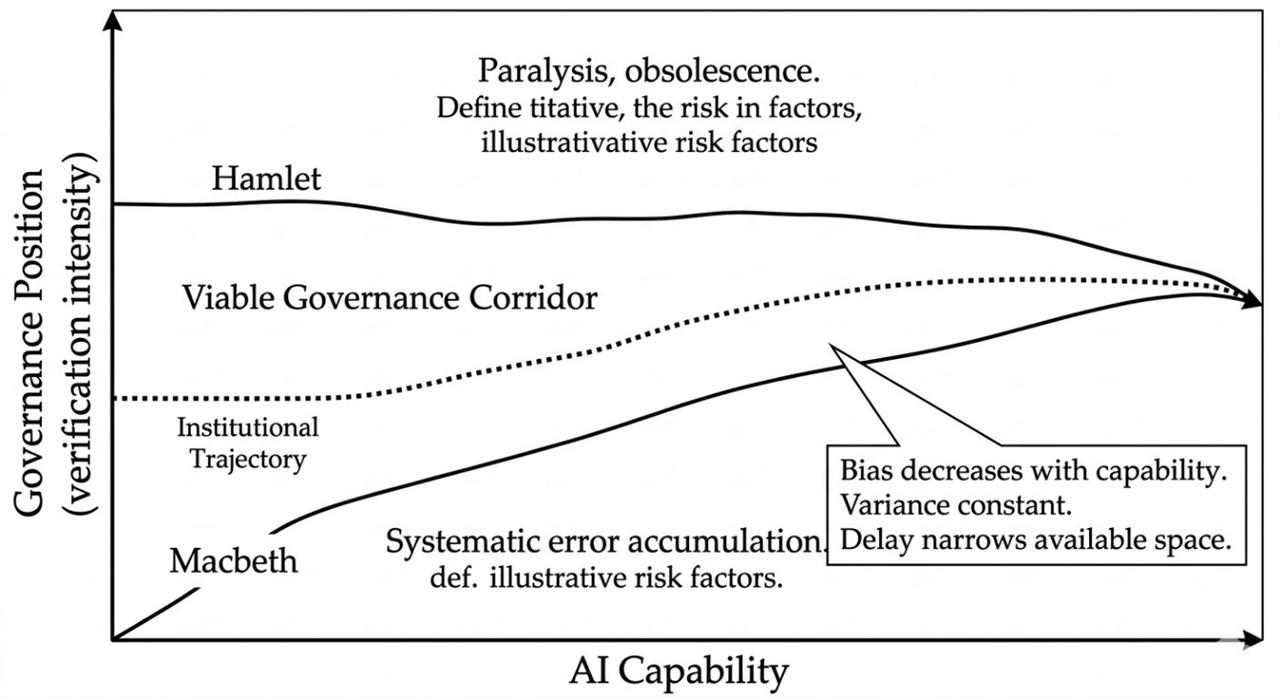
Institutional Response
Macbeth governance (high bias, low variance) over-trusts AI outputs. Hamlet governance (low bias, high variance) over-verifies and paralyses. The corridor narrows as AI capability increases. Institutional delay is itself a governance failure.
The document that specifies what must be verified, to what standard, by whom — at both personal and institutional level.
Specified points in a workflow or curriculum where AI is absent, the human produces independently, and the difference between AI-assisted and unassisted performance becomes visible. The friction is not punitive. It is architectural.
Structured, specified moments where competence is demonstrated without AI assistance. Any institution that cannot answer the question "can our people do this without AI?" has outsourced a competence assessment to the tool whose outputs it is trying to assess.
Cross-cutting
A function of two variables. First, the Competence Prerequisite: could you have produced the work independently? Second, the Verification Budget: did you apply independent verification sufficient to take intellectual ownership? The Authenticity Threshold does not offer a binary answer. It offers a structured way of asking the question honestly.
All AI-assisted attempts to mitigate AI-mediated problems are subject to the dynamics they address. The framework claims no exemption from its own analysis.
Where the framework meets practice
The concepts above are the framework. Everything that follows is built on them. This layer continues expanding as the framework is applied to new contexts.
Where Proxy Collapse is already visible
In higher education, the gap between the quality of expression and the depth of understanding in student work has become harder to diagnose. In recruitment, hiring managers are discovering that their filters were selecting for production quality rather than the competence they assumed production quality implied. In financial services, analyst reports that once took days of synthesis now arrive in minutes. In marketing, strategy documents look indistinguishable from the work of experienced strategists. In software engineering, AI-generated code that compiles and passes tests may mask whether the developer understands the architecture well enough to maintain it when the edge cases arrive.
How we measure what is happening
The rate at which unverified claims can be generated and distributed. Matters enormously in journalism, policy, legal proceedings, and any domain where assertion has outpaced verification.
How the probability of meaningful human verification changes over time as AI capability increases and institutional adaptation lags.
Applied to AI-assisted output: more content than ever, less of it saying anything new.
The gap between what AI can produce and what an institution can verify. Widest where in-house expertise is least.
What compounds over time
AI-generated content entering training data and knowledge bases that future AI outputs draw on. A contamination loop operating across the information environment.
Errors flowing downstream as one person's AI-assisted report becomes another's source material.
The gradual loosening of verification standards as AI-generated output is normalised. The slow shift from "I should check this carefully" to "this looks fine."
A systematic distortion introduced by the AI-mediated channel through which we receive evidence, unaccounted for in standard belief updating.
What this framework is not
It is not a technology critique. AI is not the problem. The problem is the interaction between human cognition and AI behaviour, operating inside institutional structures that were never designed for the conditions AI creates.
It is not a call to stop using AI. It is a call to understand what happens when we do, and to build the verification architecture that the removal of production friction has made necessary.
And it is not a list of biases with AI labels attached. It is a hierarchical framework describing the physics of a coupled system, honest about its own vulnerability to the dynamics it describes.
Where the research lives
The Mirror Effect
Eight essays building the complete framework from the ground up. Designed not to teach prompting tricks but to make visible the dynamics that even experienced users do not realise are shaping their work.
AI in Finance & Higher Education
Analytical pieces applying the framework to live developments: market reactions to capability announcements, assessment integrity challenges, and the consequences of deploying AI without verification architecture.
Original Papers & Analysis
Authored by Paul Gallacher. Peer-reviewed where published, transparently pre-print where not. All sources verified, all claims evidenced.
Practical Learning Opportunities
Structured resources for working with AI without losing independent judgement. Not prompt engineering but interaction design: how to verify what looks convincing and how to maintain critical thinking.
Start with the Mirror Effect Article Series. Eight essays, no prerequisites.
Read the SeriesPaul Gallacher
Paul is a Senior Academic at Walbrook Institute London (formerly London Institute of Banking & Finance), where he is Academic Lead for the Apprenticeship Banking, Finance & Investment Degree Provision and Undergraduate Banking & Finance programmes. A Fellow of the Higher Education Academy with chartered qualifications from the Chartered Institute of Bankers in Scotland and the Chartered Insurance Institute, he brings twenty-six years' experience across banking, asset management, derivatives trading, InsurTech, and Higher Education.
Previous roles span executive leadership, controlled function oversight, risk management, AI/ML operations, and quantitative research across regulated firms in private and listed environments. Paul has held positions as examiner with the Chartered Banker Institute and auditor with McGraw Hill, and past consultancy has spanned InsurTech, private equity, and EdTech in the UK and Middle East.
Paul has lectured extensively both domestically and internationally, including programme leadership at undergraduate and postgraduate level and international delivery in China. He has presented at international regulatory conferences on machine learning and AI, and is an Expert Delegate with the Digital Education Council on AI Usage in Higher Education.